Agent Looping Is The New Runtime
Agent looping turns manual checks into feedback cycles a coding agent can run before it comes back to you.
You ask for a change.
The agent edits the code and says it is done.
You open the app, click the same fragile flow again, check the console, notice the layout jumped, and send the agent back for another turn.
The real test was never in the prompt.
It was in your hands.
The useful phrase is agent looping.
An agent is not looping because it tries again. It is looping because it can attempt work, observe the result, verify what happened, fix what failed, and return evidence before handing control back to you.
Boris Cherny’s point is the frame: self-verification loops are what let stronger coding agents run longer without turning every task into a babysitting session. The interesting part of the video is that the verification surface is moving from deterministic project signals into encoded human taste.
Most coding-agent sessions still look turn-based:
turn-based agent loop
human verification stays in the loop
That loop works, but it keeps the human in the critical path. The agent waits for feedback because the most important checks often live outside the repository.
You know to open the app.
You know which page is fragile.
You know what a finished interaction should feel like.
You know which warning is harmless and which one means the change is not done.
The model can infer some of that from tests, typecheckers, runtime errors, and logs. But it cannot infer the whole manual verification ritual unless the ritual is written down.
That is the shift:
the workflow is not complete until the agent knows how you would check the work.
agent looping
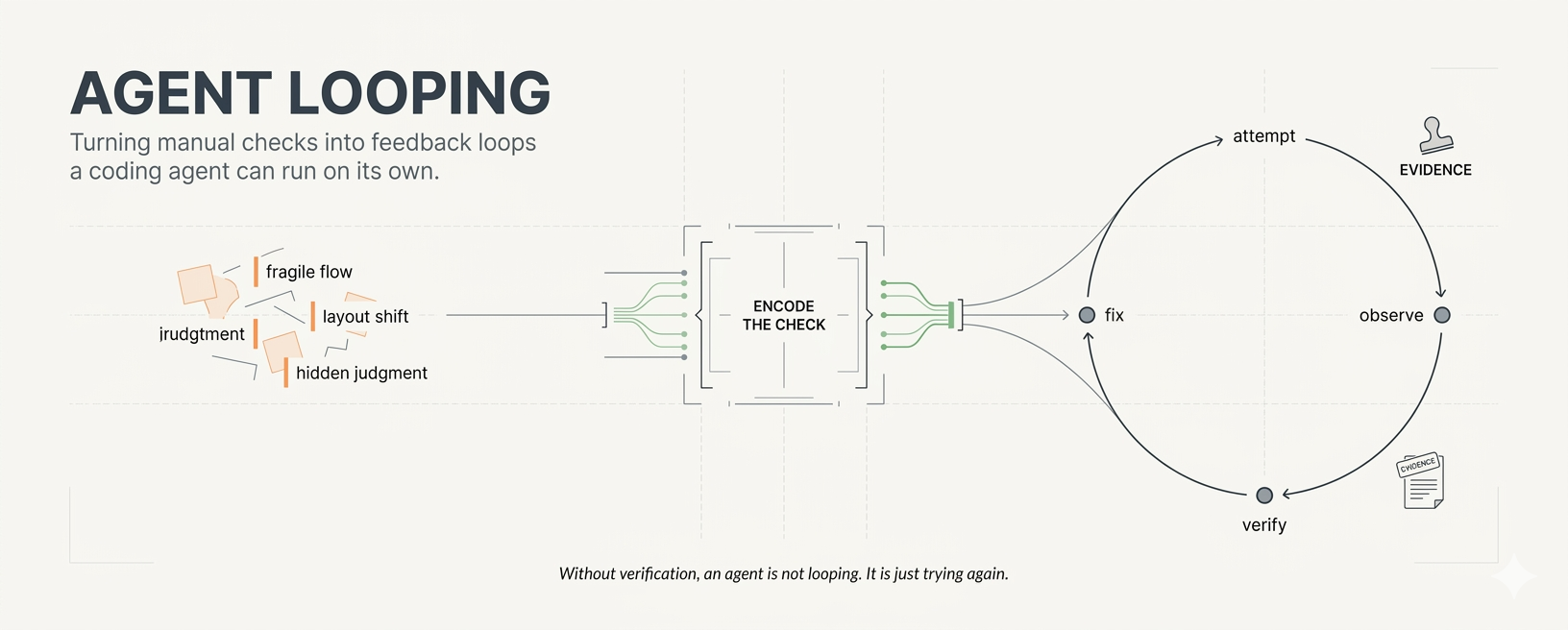
The Missing Interface
There are three kinds of feedback in an agentic coding loop.
The first is deterministic feedback: TypeScript, unit tests, integration tests, linters, CI, runtime exceptions.
The second is observational feedback: browser state, screenshots, console errors, Core Web Vitals, endpoint responses, simulator behavior.
The third is judgment feedback: “this layout moved,” “this flow feels done,” “that loading state is wrong,” “this should be reviewed by a fresh context.”
Most teams already have the first layer.
Better agent workflows encode the second and third. They turn the checks in your head into interfaces the agent can operate.
Move Checks Out Of Memory
The video gives a useful recipe:
- Write down the best-practices version of what you already do manually.
- Map each manual check to an agent-drivable tool.
- Encode that mapping as a skill.
- Have the agent run the skill while it builds, not after it finishes.
- Add an independent review layer before merge.
- Compose those layers into a shipping workflow.
Across domains, those manual checks usually collapse into the same small shape: open the surface, exercise the affected path, observe the signals, and return evidence.
For frontend work, that might mean opening the dev server, clicking the affected flow, watching the console, checking screenshots, and looking for layout shift. For backend work, it might mean hitting the endpoint, checking the response shape, reading logs, and comparing side effects. For mobile or desktop work, it might mean opening the simulator, exercising the interaction, capturing visible state, and checking runtime logs.
The important move is not the specific tool. It is making the loop legible enough that the agent can run it without asking you what “done” means.
But I Already Have Tests
Good. Keep them.
Tests are the first layer of agent looping, not the whole thing.
They tell the agent whether the code obeys deterministic rules. They do not always tell it whether the right page was opened, whether the console went noisy, whether the layout shifted, whether the loading state felt broken, or whether the change should be inspected by a fresh context.
That is why the next layer looks less like another unit test and more like a small operating manual:
- open this surface
- run this interaction
- observe these signals
- fix these failures
- return this evidence
The goal is not ceremony. The goal is to move routine judgment out of your memory and into the agent’s working environment.
Checks Need Interfaces
The video’s example is deliberately small: ask for an unrelated UI change, add a like button, then let the verification skill run.
The agent starts the dev server, opens the preview, clicks the button, confirms it works, captures a screenshot, and runs a performance trace. The task was “add a like button,” but the skill catches layout shift because layout shift is part of the encoded workflow.
That is the key idea.
The agent does not need to be told “also check layout shift” every time.
The skill carries that concern forward. The stack is simple: deterministic checks catch what is objectively broken, observational checks inspect the running system, judgment checks encode the team’s manual review ritual, and independent review gives the work a second context before merge.
The Second Agent Matters
The video ends with a point that is easy to underweight: the reviewing agent should not be the same context that wrote the code.
The builder has conversational momentum.
It knows what it meant to do.
It may over-trust its own previous decisions.
A separate reviewer starts colder. That is a feature. It is less attached to the implementation path and more likely to inspect the diff as evidence.
So the full loop is not just “agent writes, same agent checks.” A stronger loop has the builder run encoded verification during the work, then sends the diff to an independent reviewer before merge, with CI watched after handoff.
The Claude Code team’s shipping example is a useful shape: simplify the diff, run custom verification, run design checks when UI changed, open and subscribe to the PR, watch CI, and fix failures as they appear.
That is not one prompt.
That is a workflow made of skills.
Evidence Is The Handoff
An agent workflow is not mature because the agent can edit many files.
It is mature when the agent can explain how it checked the work.
The output should include evidence: commands run, pages opened, interactions tested, screenshots captured, console or log issues found, failures fixed, and remaining risks.
That evidence is what turns an agent from a fast typist into a local teammate.
The goal is not to remove humans from judgment.
The goal is to stop spending human judgment on checks the agent can learn to perform before asking for another turn.
The next runtime for coding agents is not bigger context.
It is better feedback.